PDF(3326 KB)
PDF(3326 KB)

Construction and Application Exploration of Data Foundations for Domain Large Models
Xie Wenjun, Dong Huanqing, Cao Gaohui
Knowledge Management Forum ›› 2026, Vol. 11 ›› Issue (1) : 24-39.
PDF(3326 KB)
PDF(3326 KB)
Construction and Application Exploration of Data Foundations for Domain Large Models
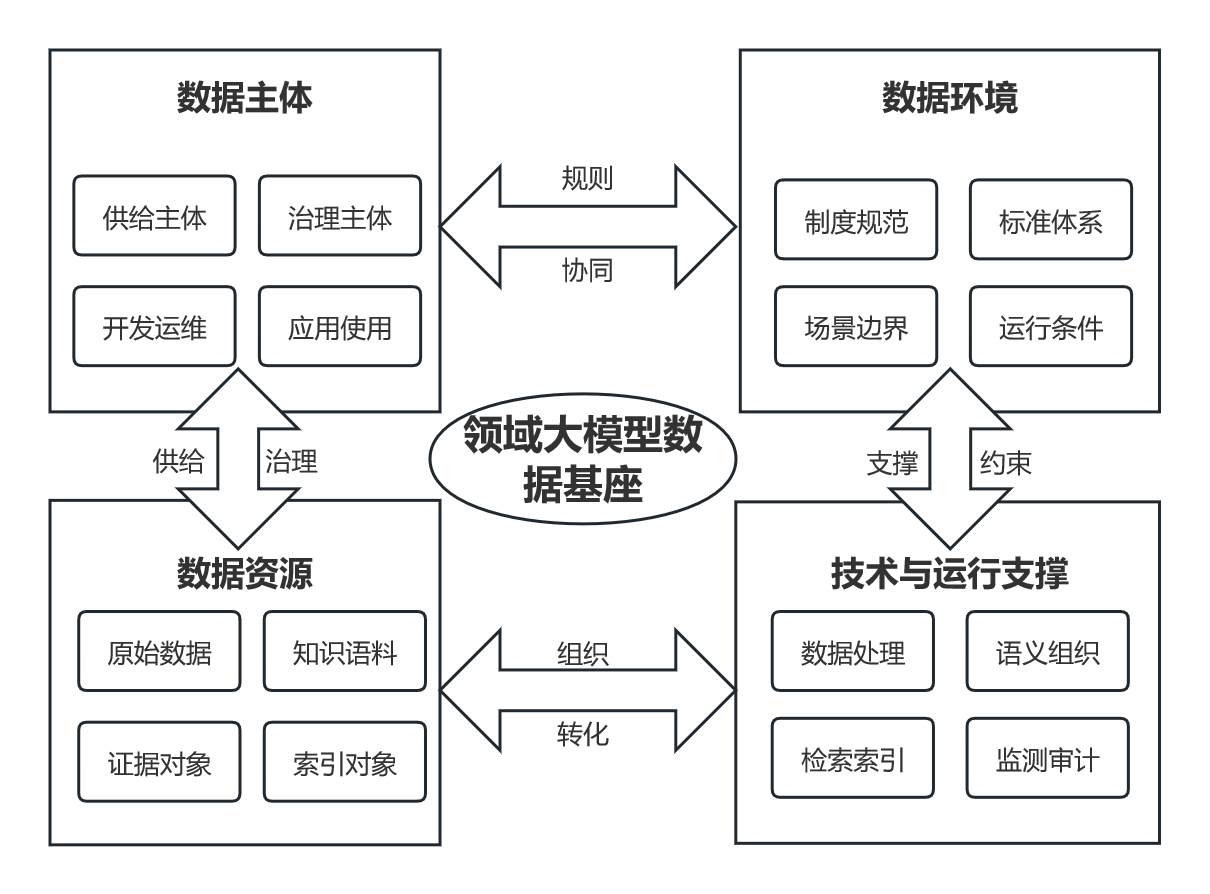
[Purpose/Significance] In response to the practical demand for high-quality data support and trustworthy operation of domain large models in specialized and high-risk application scenarios, this study systematically examines the basic connotation, key characteristics, and systematic construction path of the domain large model data foundation. It aims to provide a theoretical framework and methodological support for the practical deployment of trustworthy artificial intelligence, and to offer systematic references for the standardized construction and governance practice of the domain large model data foundation. [Method/Process] Based on a systematic review of the relevant literature, this study clarified the conceptual connotation, major characteristics, and constituent elements of the domain large model data foundation. It introduced the theory of layered modular architecture to construct a layered framework for the domain large model data foundation, mainly covering the data resource layer, knowledge organization layer, knowledge storage and semantic indexing layer, model layer, algorithm layer, application layer, and governance and operational support layer, so as to characterize the overall mechanism of the coordinated operation of data, knowledge, and models. Finally, a desk research method based on public evidence and a cross-case comparison approach were employed to demonstrate the contextual applicability of the framework. [Result/Conclusion] Cross-domain comparisons show that the proposed framework can explain the common mechanisms underlying external knowledge memory access, evidence-constrained generation, and compliance-audit output chains in reference systems across different domains. On this basis, the study further distills reusable methodological elements such as data contracts, index configuration, and evaluation baselines, thereby validating the applicability and transferability of the framework across domains.
large language models / domain large models data foundations / framework construction / application exploration
| [1] |
国务院. 国务院关于深入实施“人工智能+”行动的意见[J]. 中华人民共和国国务院公报, 2025(25):16-20.
The State Council of the People’s Republic of China. Opinions of the State Council on deeply implementing the “Artificial Intelligence+” action[J]. Gazette of the State Council of the People’s Republic of China, 2025(25):16-20.
|
| [2] |
|
| [3] |
刘学博, 户保田, 陈科海, 等. 大模型关键技术与未来发展方向——从ChatGPT谈起[J]. 中国科学基金, 2023, 37(5):758-766.
|
| [4] |
FROST & SULLIVAN CHINA. 数据基础设施白皮书[R]. 北京: Frost & Sullivan China, 2024.
FROST & SULLIVAN CHINA. White paper on data infrastructure[R]. Beijing: Frost & Sullivan China, 2024.
|
| [5] |
中国信息通信研究院. 2024年中国大模型行业应用优秀案例白皮书[R]. 北京: 中国信息通信研究院, 2024.
China Academy of Information and Communications Technology. White paper on excellent industry application cases of large models in China (2024)[R]. Beijing: China Academy of Information and Communications Technology, 2024.
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
钱力, 刘志博, 刘细文, 等. 科技文献数据资源建设模式数智化转型研究——中国科学院文献情报中心的实践探索[J]. 图书情报工作, 2025, 69(10):4-13.
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
颜航, 高扬, 费朝烨, 等. 基座模型训练中的数据与模型架构[C]// 第二十二届中国计算语言学大会论文集(卷2:前沿综述).哈尔滨: 中国中文信息学会计算语言学专业委员会,2023:1-15.
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
钱力, 张智雄, 伍大勇, 等. 科技文献大模型:方法、框架与应用[J]. 中国图书馆学报, 2024, 50(6):45-58.
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
唐悦, 马海群. 基于信息生态理论的云边协同数智专利情报服务框架构建[J]. 情报科学, 2025, 43(7):162-171.
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
徐淋楠, 邵波. 近30年图情领域ILM理论研究:热点演进、范式归纳与进路展望[J]. 图书馆理论与实践, 2022(5):9-15.
|
| [39] |
黄微, 刘逸伦, 周东阳. 基于信息生态理论的突发事件网络舆情多平台演化路径及实证研究[J]. 情报杂志, 2025, 44(9):164-175.
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
W3
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
GUU K,
|
| [50] |
李兴腾, 冯锋, 黄鹂强. 突破人工智能大模型的“数据瓶颈”——构建国家级语料库运营平台的思考[J]. 中国科学院院刊, 2025, 40(3):522-529.
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
中国信息通信研究院. 数据要素价值稳步释放——数据要素白皮书(2023年)摘编[J]. 企业管理, 2024(1):46-52.
China Academy of Information and Communications Technology. Steady release of data element value—excerpt from the white paper on data elements (2023)[J]. Business management, 2024(1):46-52.
|
| [57] |
|
| [58] |
|
| [59] |
NEURIPS 2021 Data-Centric AI Workshop. Data-centric AI[EB/OL]. [2026-01-08].
|
| [60] |
|
| [61] |
中国科学院文献情报中心. 科技文献知识人工智能引擎(SciAIEngine)[EB/OL]. [2026-01-08].
National Science Library, Chinese Academy of Sciences. Scientific literature knowledge artificial intelligence engine (SciAIEngine)[EB/OL]. [2026-01-08].
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
/
| 〈 |
|
〉 |