PDF(1511 KB)
PDF(1511 KB)
 PDF(1511 KB)
PDF(1511 KB)
PDF(1511 KB)
PDF(1511 KB)
一种结合字面与上下文相似性的招聘网页技能词语规范化方法
A Skill Vocabulary Normalization Method for Recruitment Webpage Combing Literal and Context Similarity
 ,
,
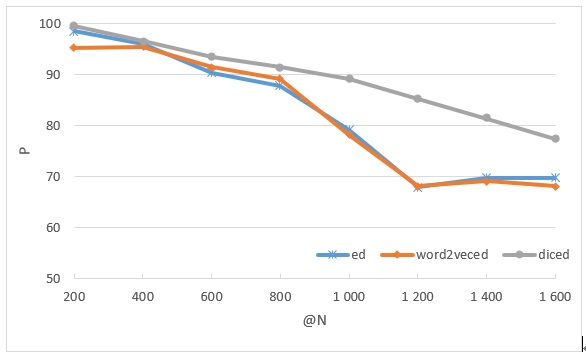
[目的/意义] 针对招聘网页文本存在许多英文技能词语拼写错误的问题,提出一种招聘网页技能词语规范化方法。[方法/过程] 结合字面相似性和上下文相似性,度量技能词语的相似度,形成相似技能词语网络,从而对招聘网页文本中的技能词语进行规范化。[结果/结论] 从国内主流招聘网站前程无忧获取一周计算机类岗位求职信息,使用提出的方法进行招聘网页英文技能词语规范化。实验结果表明,提出的方法能够自动、准确、快速地规范招聘网页文本中的技能词语。
[Purpose/significance] This paper proposes a skill vocabulary normalization method for recruitment webpages, it aims to solve the problem that many English skill word spelling errors exist in the recruitment webpages. [Method/process] The method combines literal similarity and context similarity to measure the similarity of skill word and form a similar skill word network to normalize the skill words in the recruitment webpages. [Result/conclusion] One week’s computer recruitment information was obtained from domestic mainstream recruitment website 51job to evaluate the proposed method. The experiment results show that the proposed method can automatically, accurately and quickly normalize the skill vocabulary in the recruitment webpages.
| [1] |
WOWCKO I. Skills and vacancy analysis with data mining techniques[J]. Informatics, 2015, 2(4):31-49.
|
| [2] |
KIM J Y, LEE C K. An empirical analysis of requirements for data scientists using online job postings[J]. International journal of software engineering and its application, 2016, 10(4): 161-172.
|
| [3] |
夏火松, 潘筱听. 基于Python挖掘的大数据学术研究与人才需求的关系研究[J]. 信息资源管理学报, 2017, 7(1): 4-12.
|
| [4] |
詹川. 基于文本挖掘的专业人才技能需求分析——以电子商务专业为例[J]. 图书馆论坛, 2017, 5(1): 116-123.
|
| [5] |
夏立新, 楚林, 王忠义,等. 基于网络文本挖掘的就业知识需求关系构建[J]. 图书情报知识, 2016, 169(1):94-100.
|
| [6] |
刘睿伦, 叶文豪, 高瑞卿, 等. 基于大数据岗位需求的文本聚类研究[J]. 数据分析与知识发现, 2017, 12(12): 32-40.
|
| [7] |
LUO Q, ZHAO M, JAVED F, et al. Macau: large-scale skill sense disambiguation in the online recruitment domain[C]// IEEE international conference on big data. Piscataway: IEEE, 2015:1324-1329.
|
| [8] |
BRILL E, MOORE R C. An improved error model for noisy channel spelling correction[C]// Meeting of the Association for Computational Linguistics. Piscataway: IEEE, 2000:286-293.
|
| [9] |
TOUTANOVA K, MOORE R C. Pronunciation modeling for improved spelling correction[C]// Proceedings of annual meeting of the Association for Computational Linguistics. Stroudsburg :Association for Computational Linguistics, 2002:144-151.
|
| [10] |
CHOUDHURY M, SARAF R, JAIN V, et al. Investigation and modeling of the structure of texting language[J]. International journal of document analysis & recognition, 2007, 10(3):157-174.
|
| [11] |
LIU F, WENG F, WANG B, et al. Insertion, deletion, or substitution? normalizing text messages without pre-categorization nor supervision[J]. 2012, 15(2):71-76.
|
| [12] |
AW A T, ZHANG M, XIAO J, et al. A phrase-based statistical model for SMS text normalization.[C]//International conference on computational linguistics and meeting of the Association for Computational Linguistics. New York: ACM, 2006: 17-21.
|
| [13] |
PENNELL D L, LIU Y. A character-level machine translation approach for normalization of sms abbreviations[J]. Natural language processing, 2011,20(2):974-982.
|
| [14] |
COOK P, STEVENSON S. An unsupervised model for text message normalization[M]. Stroudsburg:Association for computational linguistics, 2009.
|
| [15] |
SRIDHAR V K R. Unsupervised text normalization using distributed representations of words and phrases[C]// The workshop on vector space modeling for natural language processing. Piscataway: IEEE, 2015:8-16.
|
| [16] |
施振辉, 沙灜, 梁棋,等. 基于字词联合的变体词规范化研究[J]. 计算机系统应用, 2017, 26(10):29-35.
|
| [17] |
罗延根, 李晓, 蒋同海,等. 基于词向量的维吾尔语词项归一化方法[J]. 计算机工程, 2018(2):220-225.
|
| [18] |
DAMERAU F J. A technique for computer detection and correction of spelling errors[J]. Communications of the ACM, 1964, 7(3):171-176.
|
孙瑜: 提出研究思路,实施实验,撰写论文;
姜金德: 分析实验数据,修改论文,进行理论指导。
/
| 〈 |
|
〉 |